3、InnoDB索引结构和原理
INFO
简单介绍InnoDB的主键索引和二级索引的基本结构,以及如何利用索引进行查询的,包括回表和索引覆盖的概念等
1、InnoDB的索引结构
前面讲到,InnoDB索引分为clustered索引和secondary索引,或者叫聚簇索引和非聚簇索引,或者叫主键索引(通常情况下clustered索引也叫主键索引)和二级索引。InnoDB的索引结构是一棵B+树。
1.1、主键索引
在InnoDB中,主键索引一般就是作为clustered索引,如果没有定义主键索引,那么InnoDB会将第一个的非空的唯一索引作为clustered索引,如果连一个非空的唯一索引都没有的话,系统会自动在一个由rowid合成的列上建立一个名为GEN_CLUST_INDEX 的索引作为clustered索引。rowid是6个字节长度的随着数据插入自增的并且物理上有序的列。
一个表只有一个聚簇索引(很容易理解,因为数据保存在聚簇索引中,对于一个表也只需要保存一份数据就可以了)
主键索引的结构大致如下图所示:
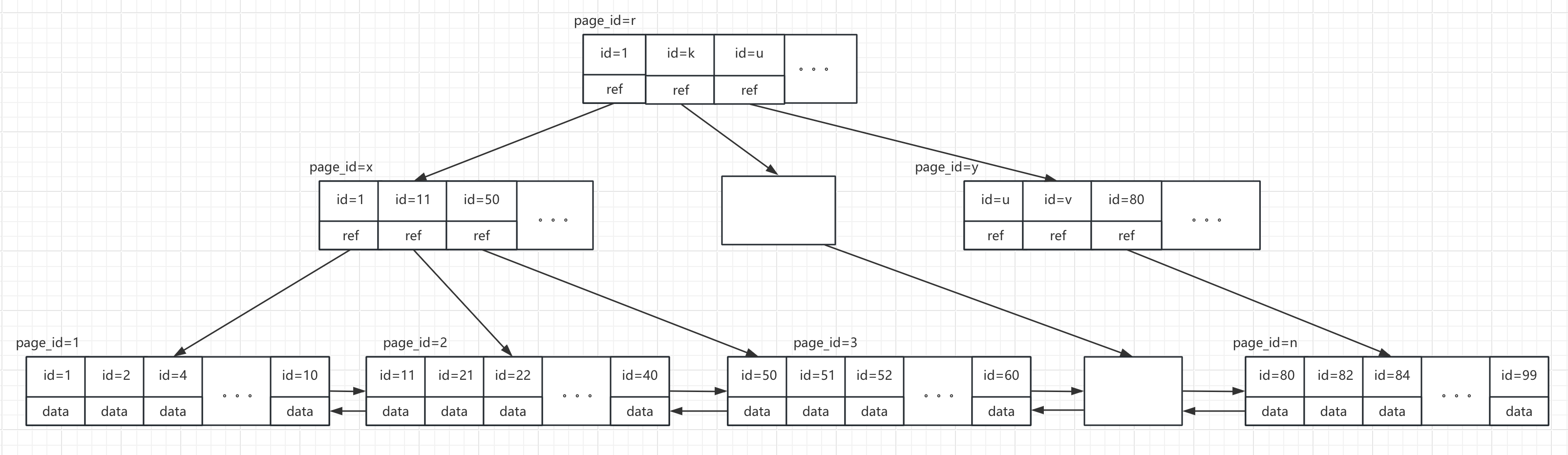
- 整体是一棵B+树
- 非叶子节点是以id为键的树的节点
- 树的叶子节点保存行数据
- 所有非叶子节点是一个以ID为排序的单向链表(图中未表示出来)
- 所有叶子节点又以是以id排序的一个双向链表
B+树是一棵平衡查找树,对比普通的平衡二叉树(比如红黑树),可以看到B+树的“分叉”更多,这有什么好处呢?从大自然的现象就能看出点端倪。比如一棵树它的树杈特别多,总体给人的一种感觉就是枝繁叶茂特别“丰满”,而一些看起来“瘦高”的树基本上都没有多少树杈。那么问题来了,同样品种的树,是一棵“瘦高”的树的树叶多呢看是一棵看起来就很“丰满”的树的树叶多呢?直觉告诉当然是后者。同样的,数据库里一行行的数据就好比一片片的树叶,作为多路查找树的B+树当然在同等的条件下能够容纳更多的数据。
这里没讲什么科学的大道理,完全是基于常识和直觉来判断的。但是有人可能会问了,B树也是多路查找树,为什么InnoDB选择B+树而不用B树呢?
B+树与B树的区别主要在于B树的非叶子节点会存储数据,而B+树的数据全部存储在叶子节点。这有什么好处呢?
首先,每个节点的大小是有限的,如果将数据存储在各节点上,那么节点所能保存的索引值就会更少,这样树的深度就会变大,I/O的次数也就会更多。其次,数据保存在非叶子节点上,对于每次查询,可能有的key查询一次在根节点上就可以得到想要的数据了,也就不用继续往后走了,而对于有的key仍然可能要一直走到叶子节点才能拿到对应的数据,这样查询性能就会很不稳定。最后,在范围查询的场景下,B+树由于所有的数据都保存在叶子节点中,并且是一个有序链表的形式,所以只需要顺着链表指针往下扫就可以了,而对于B树而言数据都是存储在各个节点上,所以需要多树进行中序遍历才能得到目标数据。
这样,如果要检索id=xxx的记录,则从B+树的根节点开始二分查找,根据xxx的值从page页区间比对找到所在的page页,然后到指定的叶节点的page中找到对应的值。
正是因为检索是从根节点开始查找索引树,所以为了提升查询性能,需要尽可能减少I/O的次数,换句话说就是需要控制好树的深度。其中就有几个因为会影响B+树的深度:
- page页大小
- key值的长度
1.2、二级索引
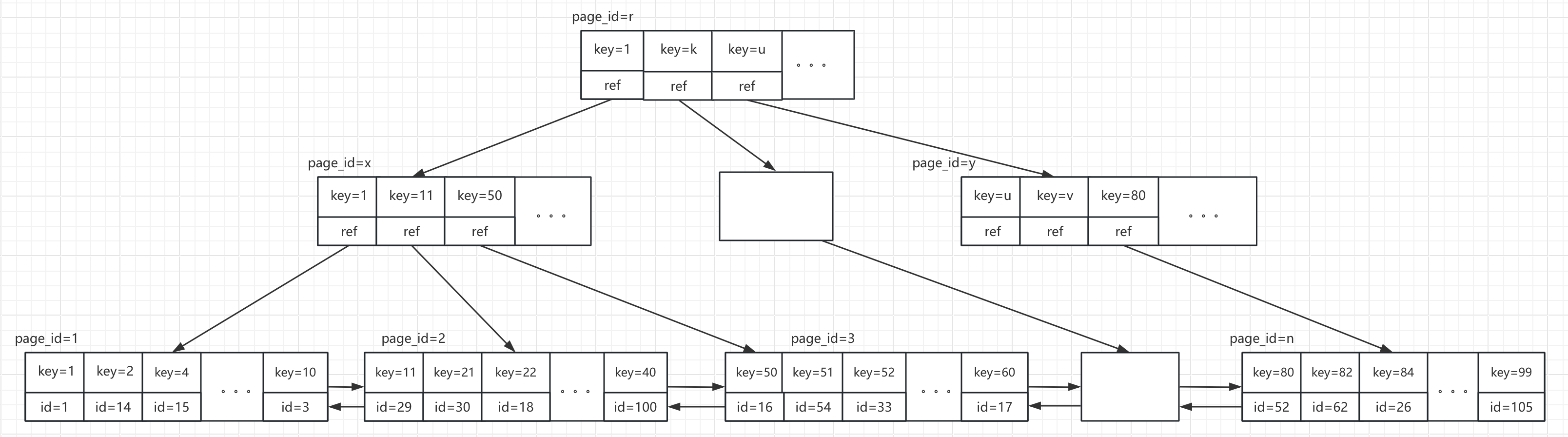
InnoDB的二级索引是除主键索引之外的索引,它的结构类似于主键索引,只不过它的叶子节点存储的不在是数据行了,而是数据行对应的记录ID,大概如下图所示:
2、索引原理
2.1、索引的工作流程
在日常的数据库开发中,我们为了加快数据查找的速度,在绝大部分情况下会优先考虑对我们要查找的列添加索引。很多时候,添加索引就意味着查询性能的提升。
那么索引是如何提升查询性能的呢?类比学习法,所谓索引,就好比我们小学时候查《新华字典》的目录。
假如给一个完全不懂中文的老外一本《字典》,如果你让他查某个字,他会怎么查呢?拼音也不懂拼音,偏旁部首更是完全一脸懵逼,估计他能做的就只有一页一页地翻,直到找到和你给定的这个字形完全一样的字。
假如同样给一个学会了拼音的小学生一本《字典》,并且你告诉了他这个字的读音,那么他是不是就可以在目录部分找到对应的声母,然后根据韵母相同的部分,然后就可以定位到对应韵母的页数,然后在这个范围里查询就可以了
同样的道理,如果要检索的数据没有索引的话,想要查询某个值,数据库可能会采用最傻的方式-全表扫描。这样如果数据量比较大的情况下速度就会很慢,如果刚好要查询的这个列有索引呢?假设有一张表的数据如下:
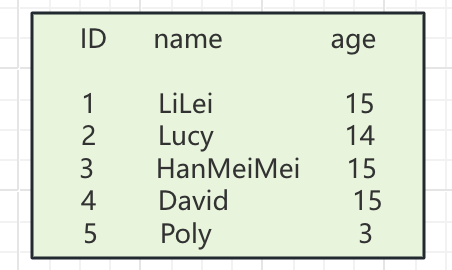
对应主键索引大意如下:
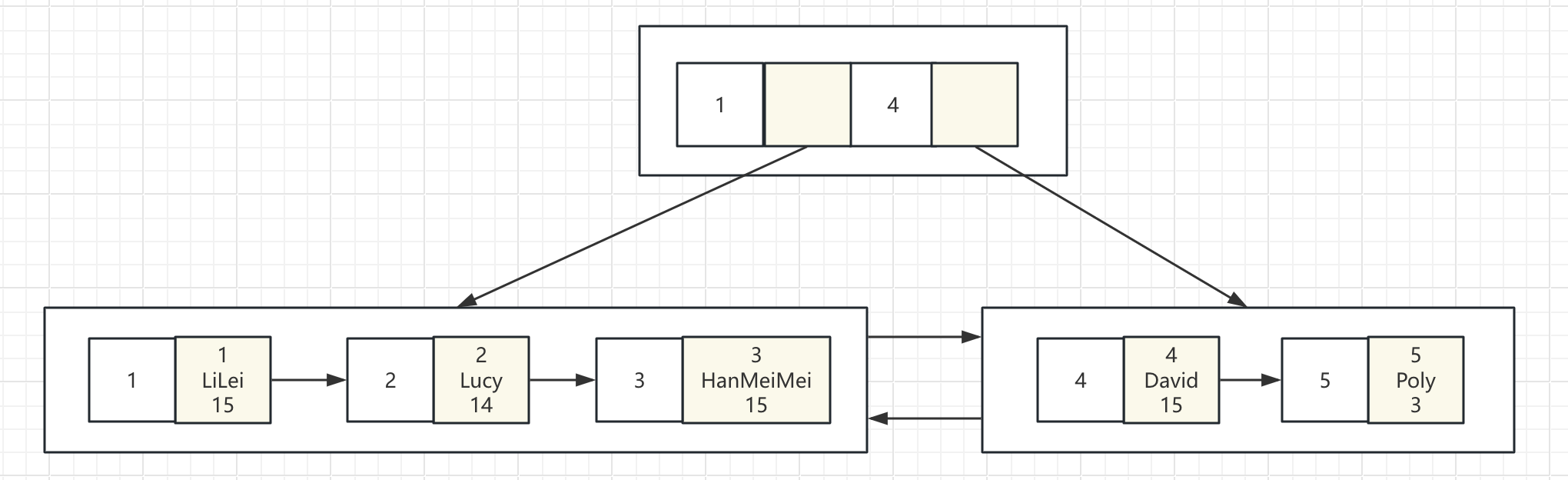
在name列上建了一个索引,索引结构大意如下:
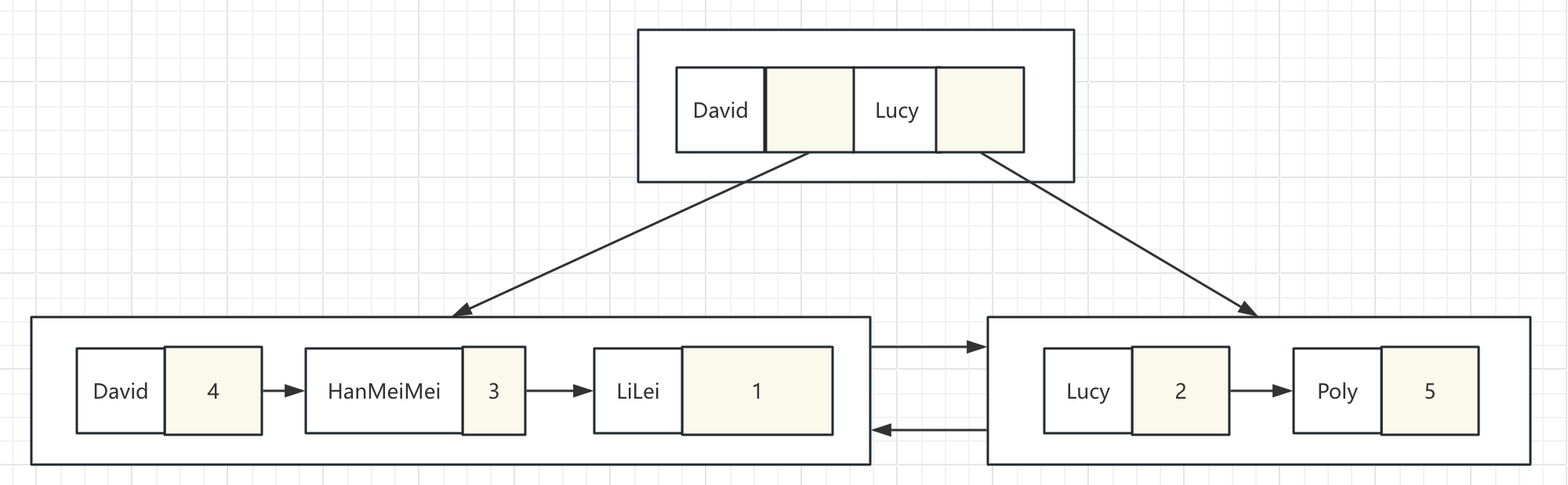
假如查询select * from table_name where name=“xxx”:
①、 首先根据给的这个值,在二级索引树中从根节点开始查找,比对给定的这个值和key的大小,如果小于最小的key,则走最小的key的下一个节点去查;如果大于最大的那个key,则走最大值的那个key的下一个节点;如果刚好等于某个值,就找对应这个值的下一个节点;如果在某两个key之间,就分别从这两个key的下一个节点去找
② 、重复上一步的key值比较,一直查到某个叶子节点
③ 、如果最终的叶子节点里的每个key都和目标key不一样,则表示没有找到对应的数据,否则,由于叶子节点保存的是对应记录的ID,所以就可以拿到给定的这个key值对应数据的id
④ 、拿到对应数据的ID后,如果需要查找的信息中包含这棵二级索引树中不存在的列,则需要从主键索引中根据对应的ID值再去查这条数据的详细数据
2.2、回表
上面这个查询的第四步,根据name="xxx"在二级索引树的叶子节点里找到的对应的id,重新回到主键索引去查找对应记录的详细数据,这个过程就叫回表
回表的过程又是一次树查找的过程,这些都是I/O操作,会影响性能的。但是MySQL数据库为了平衡数据查找的时间和数据存储的空间设计了这样的索引结构,总之比较理想的状态就是像主键索引查找那样,一次性就拿到想要的数据。
2.3、覆盖索引
我们知道一般情况下主键索引的效率会比二级索引效率会高,其中的差别就在二级索引的“回表”过程。如果能够不需要回表就好了,直接查完二级索引后就能拿到想要的数据返回了。
但是二级索引上又只有索引key和对应记录的ID。然而,也并不是所有的查询我们都需要select *的。如果刚好我们要的就只有key对应的这个列以及id列而不需要其它列呢?
这时候当然就不用再傻乎乎地去再查一遍主键索引了。
对于这种我们要查询的数据列刚好就是索引列或ID列的场景,我们称为覆盖索引
