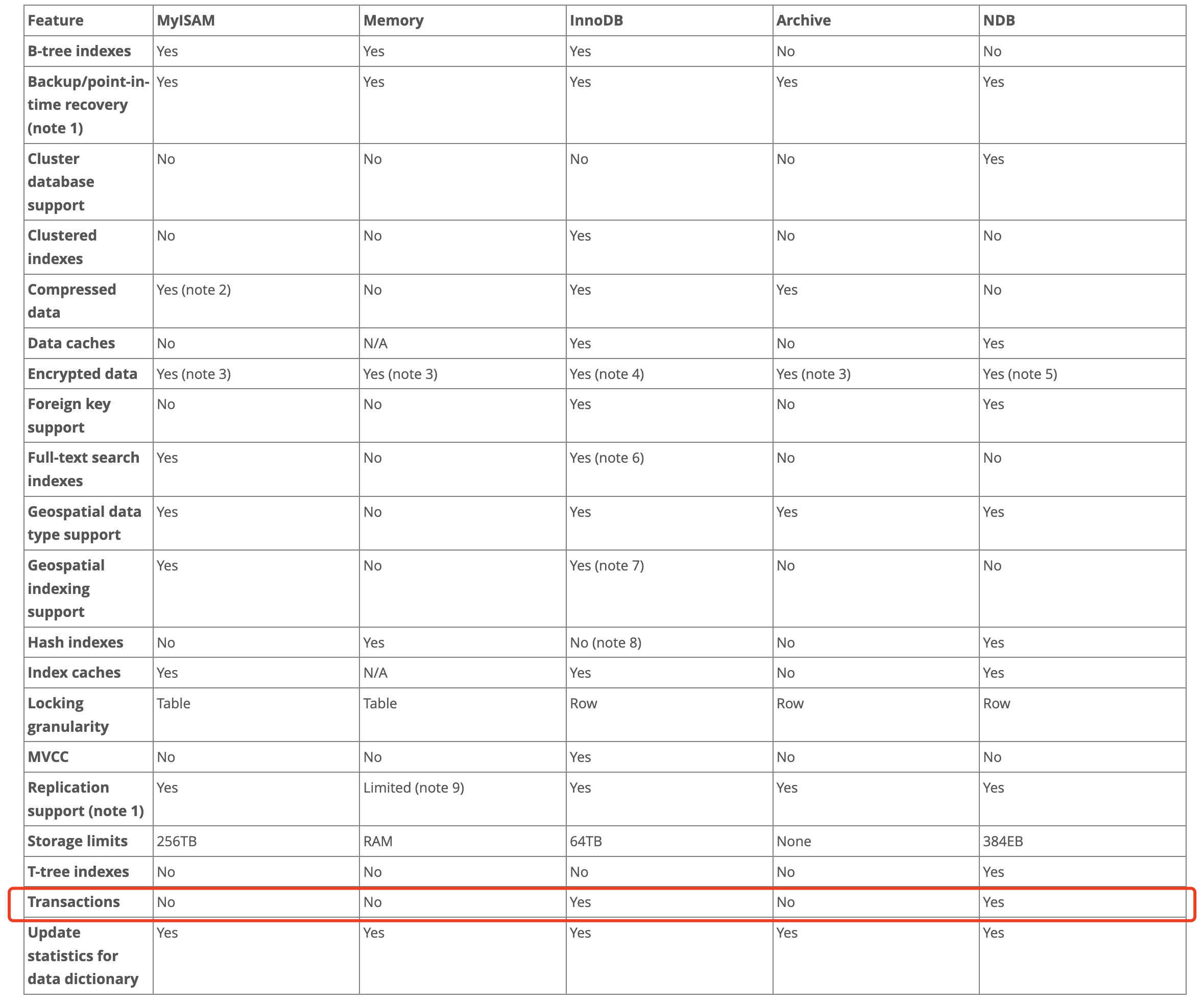
5、MySQL事务特性和事务隔离级别
INFO
简单分析事务的ACID特性和存在的数据一致性问题,再介绍了一下MySQL的事务隔离级别
1、MySQL的事务特性
事务是工作的原子单元,可以提交或回滚。当事务对数据库进行多个更改时,要么在事务提交时所有更改都成功,要么在事务回滚时所有更改都被撤消。
但是在MySQL常用的这些存储引擎中,也只有InnoDB存储引擎才支持事务
从事务的概念出发,事务的特性表现在以下四个方面
1.1、原子性
所谓原子性(Atomicity),就是我们的多个操作是一起执行的,要么一起提交,要么一起回滚。主要是通过commit、rollback、autocommit来控制事务的提交与否
但是数据库默认是自动提交的,比如我们用navicat执行一个DML语句,事务会在我们语句执行完成后自动提交。想要手动提交事务,就需要用begin或者start transaction手动开启一个事务,或者将autocommit设置为false
数据库的原子性和我们之前学习并发编程的时候提到的“原子性”有点相似,但还是有一些不一样的。并发编程里的原子性主要表现在一个线程对一个资源操作的时候其它线程不能同时去动它,而数据库事务里的原子性重点在要么同时提交,要么一起回滚。
1.2、一致性
数据库的一致性(Consistency),顾名思义就是要保证数据库数据的一致性。不能因为外界的一些因素,比如突然断电等的影响而出现和预期的不一致的情况。
数据库在保证一致性方面有哪些机制呢?
首先就是双写机制,也就是doublewrite。数据库在将有数据更新的脏页写入磁盘之前会有一个双写的过程,由于这个过程是顺序I/O,性能比刷脏时候的随机I/O强很多,所以基本上能保证提交的数据能够被“备份”到doublewrite空间
其次,InnoDB为了应对MySQL突然崩溃的场景准备了一个redolog,前面在介绍InnoDB的表空间的时候提到这块空间有一个独立的redolog表空间。它的工作原理和doublewrite类似,就是在数据提交的同时会写一份redolog日志,也是顺序I/O,如果真的碰到了MySQL崩溃的情况,在下次服务起来的时候会从redolog日志中进行数据恢复。
1.3、隔离性
隔离性(Isolation)是指不同事务对数据的操作对彼此的影响。这块直接关系到我们读取的数据是否是我们理想的数据,也是我们讨论最多的一个特性。这里留到后面讲事务的隔离级别的时候细聊。
1.4、持久性
事务的持久性(Durability)毫无疑问,比如已经被事务提交的数据不能平白无故地丢了,必须要尽可能地同步到磁盘做好持久化。
为了保证事务的持久性,InnoDB主要依赖以下几个重要机制:
- 双写,保证内存同步到磁盘,就算page损坏的情况下也能恢复。
- RedoLog机制
- binlog的同步机制
- 独立表空间或者系统表空间 设置
2、事务的隔离级别
2.1、数据一致性问题
数据的一致性问题是我们最关心的问题之一,也是讨论最多的问题,经常在面试中也会被问到有哪些数据一致性问题,MySQL是如何解决的。
- 脏读
所谓脏读就是一个事务读取到了另外一个线程还没提交的数据。如果这时候给它读出来了,回头人家转过头就回滚了,那读到的就是一条不应该存在的数据
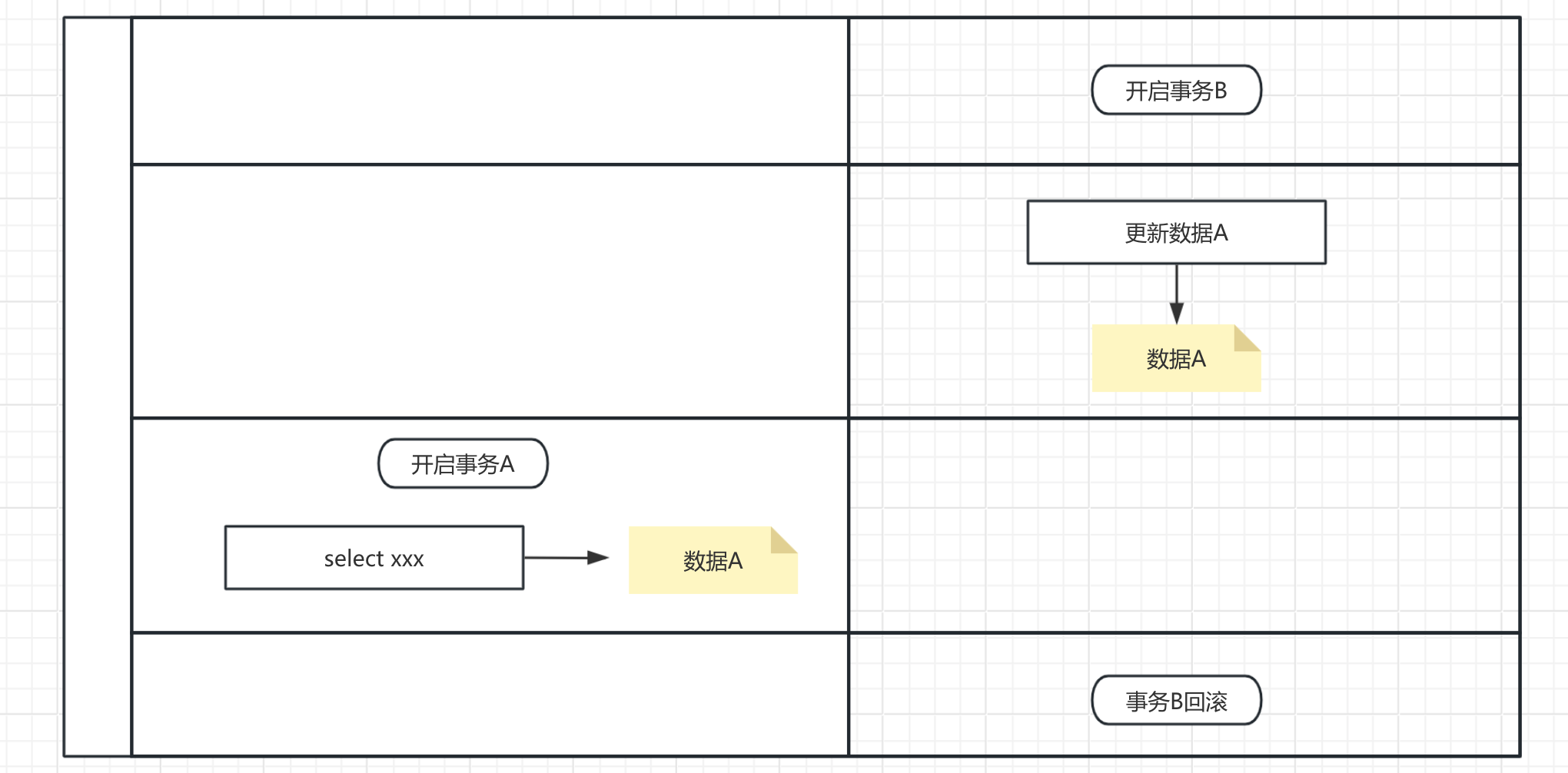
像这样一个事务读到另外一个事务未提交的数据,这就叫脏读
- 幻读
当一个事务在进行范围查询的时候,另外一个事务刚好往这个范围区间内插入了新的记录,导致第一个事务前后查询的时候查出来的结果不一致,这就叫幻读,如下图所示:

第二次查询可能就会比第一次查询多出来一条
- 不可重复读
当一个事务查询数据的时候,另外一个事务对这个数据进行了修改或者删除,导致第二次查询的时候查询出来的结果和第一次查询的结果不一样,如下图所示:

这个时候第二次查询的优惠券码就是
723532了,而不再试第一次查询得到的结果
这种场景下出现前后两次查询的结果不一样的问题叫不可重复读问题
2.2、MySQL的事务隔离级别
出现上述数据一致性问题基本上都不是我们原因看到的,为了解决这些问题,SQL标准定义了四个事务隔离级别:①读未提交(Read UnCommitted)、②读已提交(Read Committed)、③可重复度(Repeatable Read)、④串行化(Serializable)
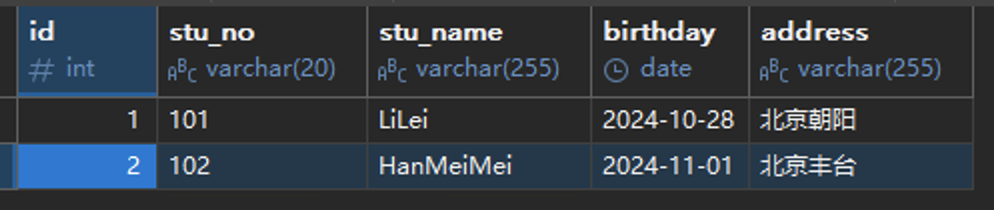
假设我们有一张学生表,下面示例以这张表为例:
CREATE TABLE `student` (
`id` int NOT NULL AUTO_INCREMENT COMMENT '主键id',
`stu_no` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '学号',
`stu_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '姓名',
`birthday` date DEFAULT NULL COMMENT '出生日期',
`address` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT '家庭住址',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_stu_no` (`stu_no`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci COMMENT='学生表';
表中有两条数据:
- 读未提交(RU)
前面提到如果一个事务去读另一个事务未提交的数据,会出现脏读的问题,接下来模拟两个事务
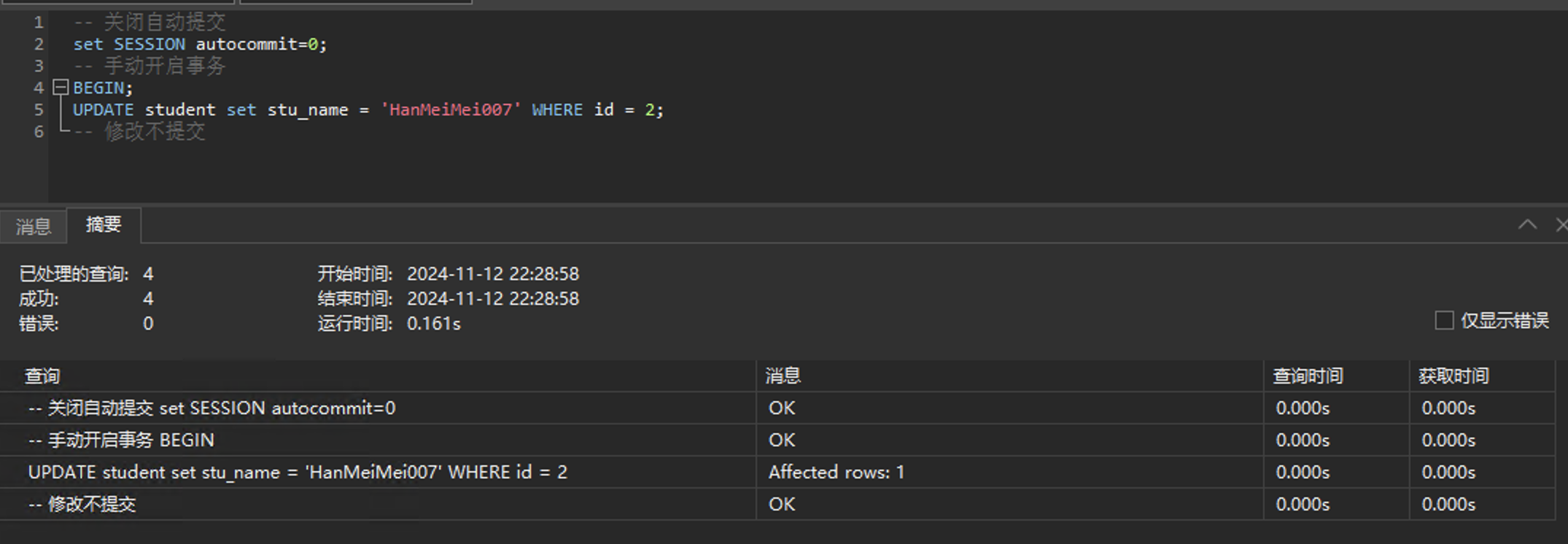
事务A修改一条数据,但是不提交:
-- 关闭自动提交
set SESSION autocommit=0;
-- 手动开启事务
BEGIN;
UPDATE student set stu_name = 'HanMeiMei007' WHERE id = 2;
-- 修改不提交
执行:
事务B在读未提交的隔离级别下去读
-- 将事务隔离级别设置为RU
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
-- 查询
SELECT * FROM student;
执行,看能不能查到那条未提交的脏数据:
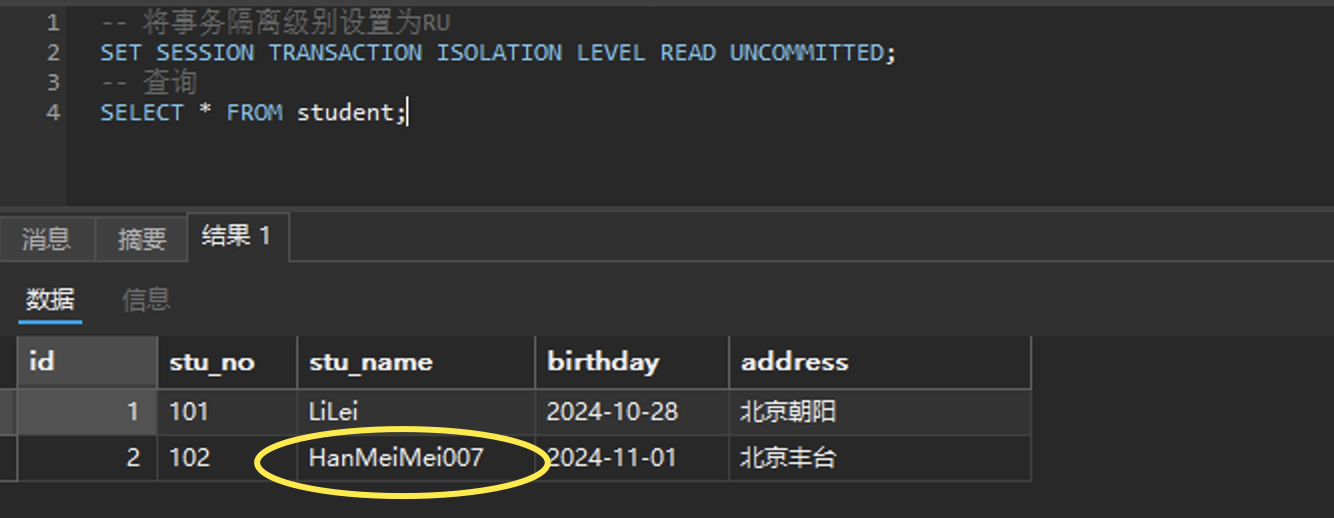
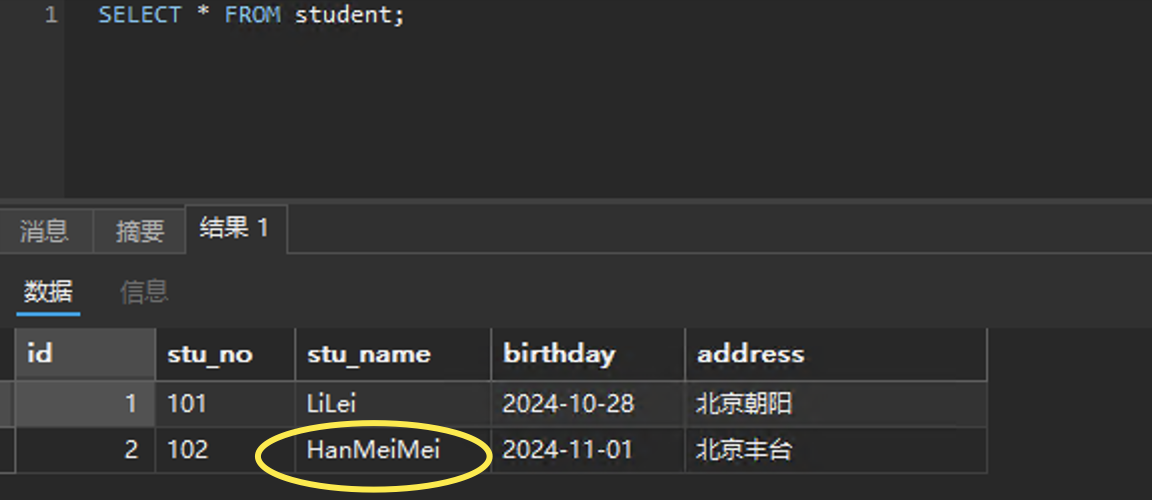
其实默认的RR隔离级别下是看不到的:
- 读已提交(RC)
为了解决脏读问题,我们可以将隔离级别设置为RC。那么在RC级别下是否真正解决了脏读的问题呢?我们来验证一下。
首先查询一下前面没提交的修改,看在RC下能读到吗
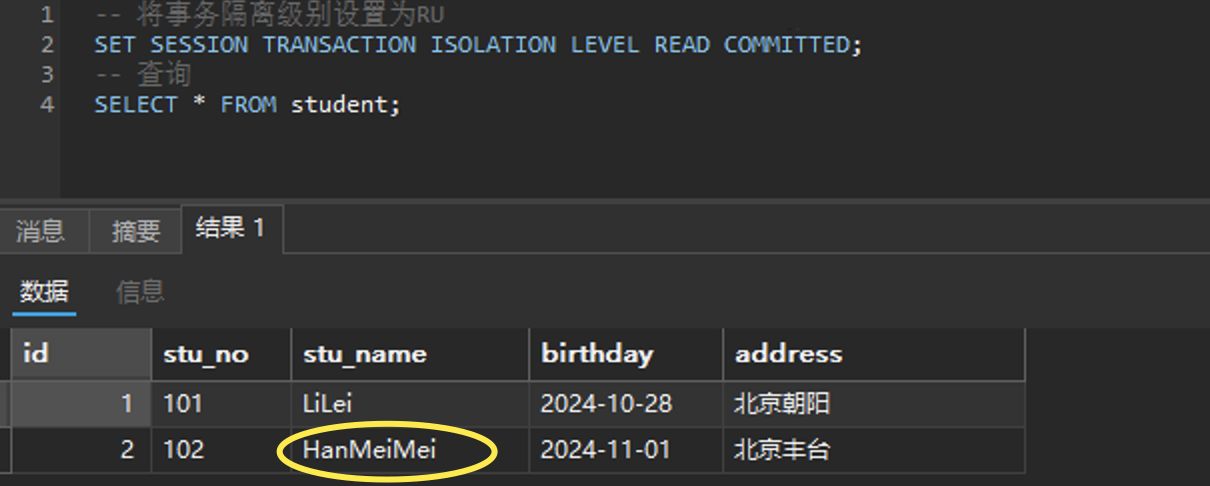
可以看出来没有读到
接下来还是用两个事务,事务A仍然是去修改一条数据,但是和前面不同的是他修改完就提交了
-- 关闭自动提交
set SESSION autocommit=0;
-- 手动开启事务
BEGIN;
UPDATE student set stu_name = 'HanMeiMei007' WHERE id = 2;
COMMIT;
-- 修改后提交
执行:
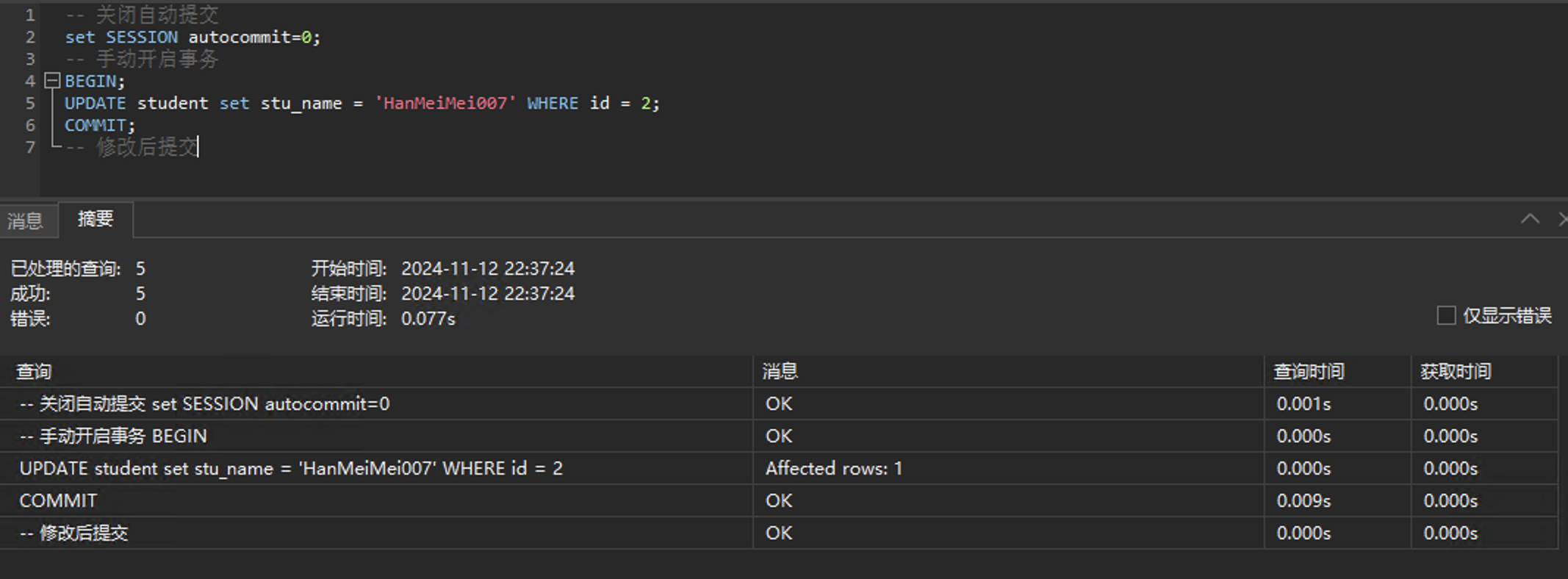
接下来会话B模拟读已提交下的事务B去查询:
-- 将事务隔离级别设置为RU
SET SESSION TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- 查询
SELECT * FROM student;
执行:
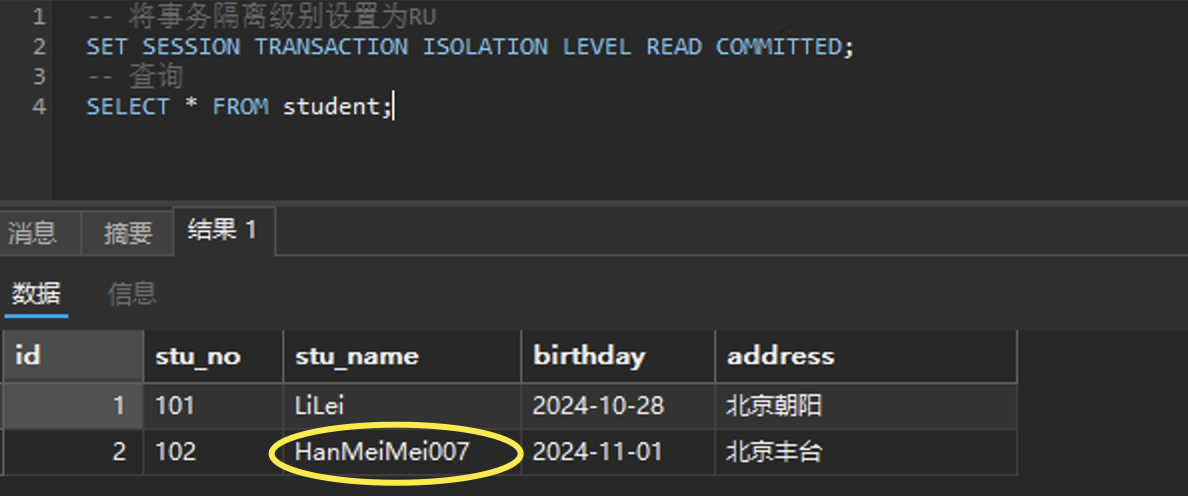
可以看到能够正常读取到已经提交的数据。
所以可以看出来,RC隔离级别确实解决了脏读的问题
- 可重复读(RR)
都说可重复度解决了脏读、幻读、不可重复读的问题,同样也来验证一下
首先验证脏读问题,还是会话一修改不提交:
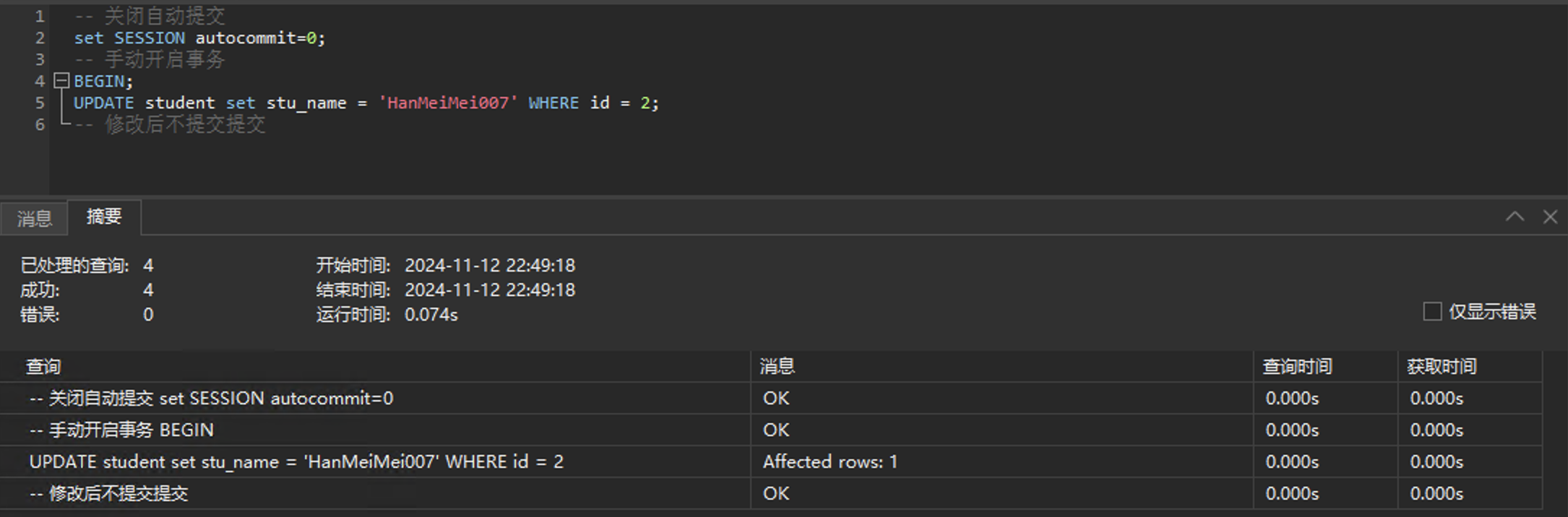
会话二用RR级别去查一下,看能不能查到这条未提交的数据:
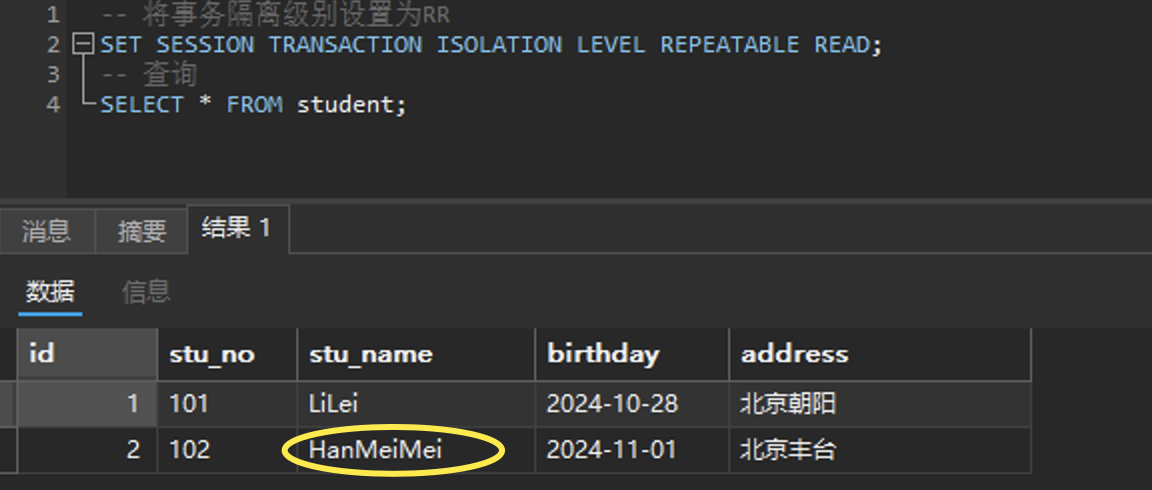
可以看到没有查到
接下来验证一下不可重复读,会话一去查数据:
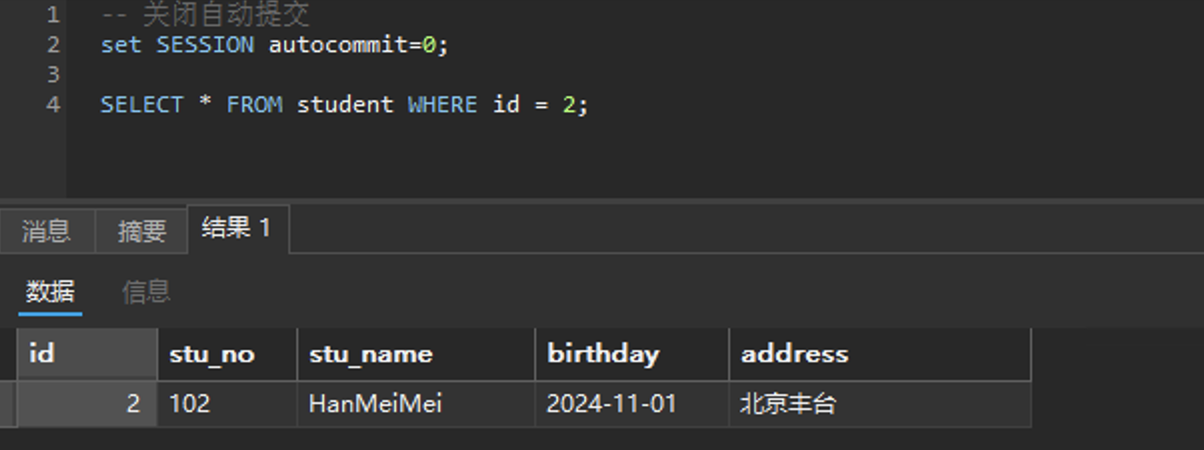
会话二去修改这条数据:
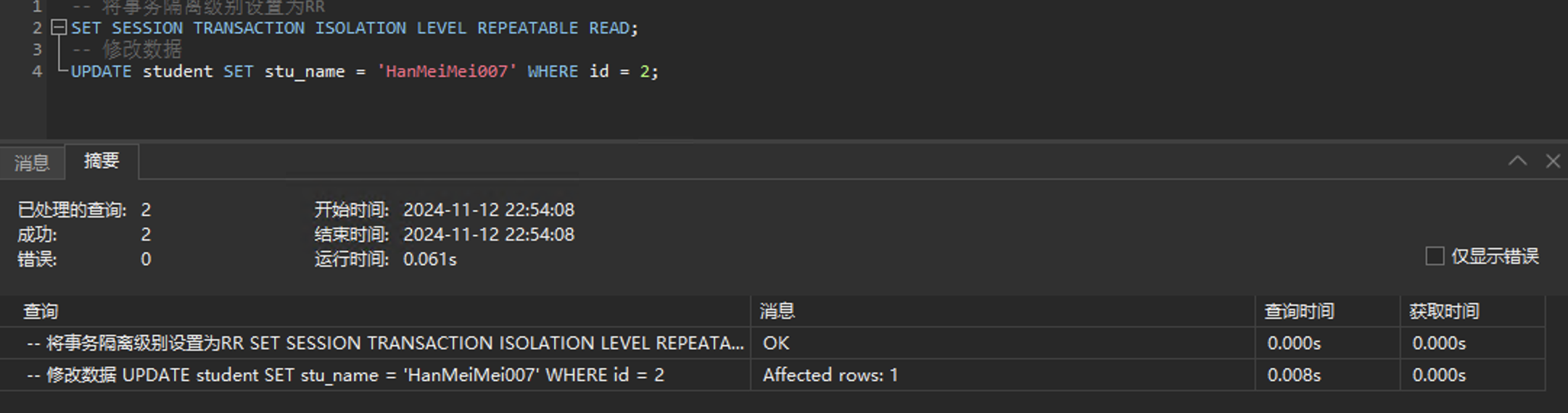
可以看到也修改成功了,那么会话一再去查结果会和第一次查询一样吗?
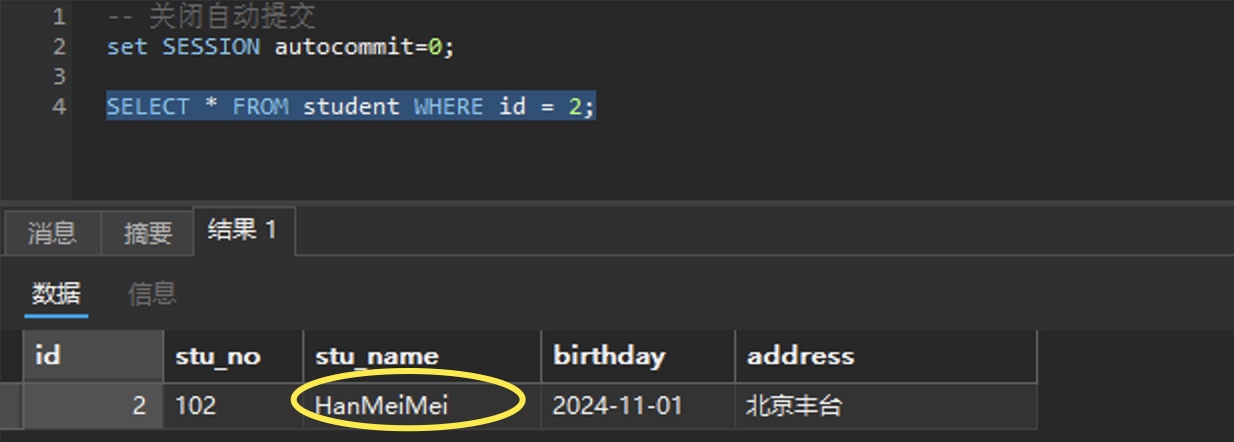
可以看到还是和原来的一样,也就是说解决了重复读的问题
那么幻读真正的解决了吗?我们也来验证一下
会话一去查询学号大于1的学生:
BEGIN;
SELECT * FROM student WHERE id > 1;
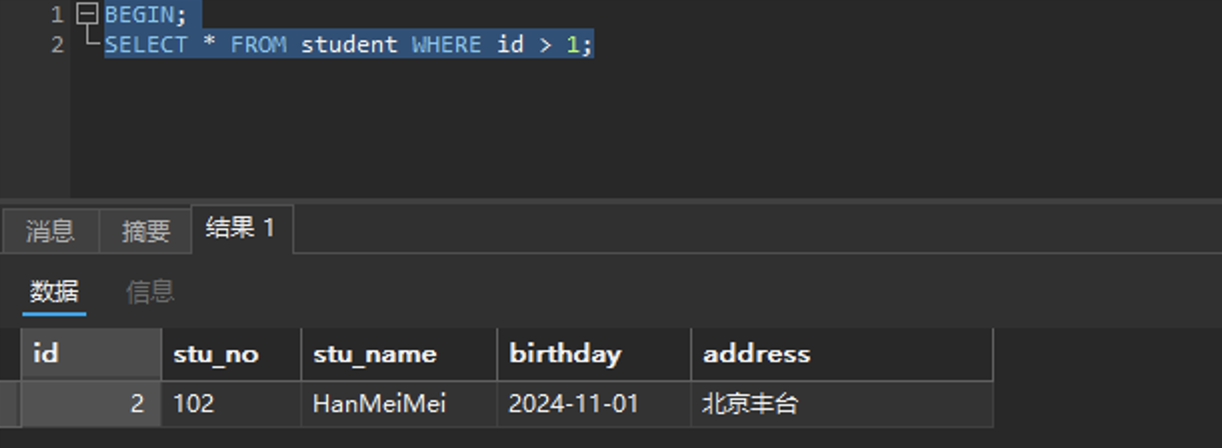
可以看到只有一条
接下来会话二插入一条记录:
-- 将事务隔离级别设置为RR
SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- 插入数据
INSERT INTO student(id, stu_no, stu_name, birthday, address) VALUES(3, '103', 'David', '2019-08-20', '美国华尔街')
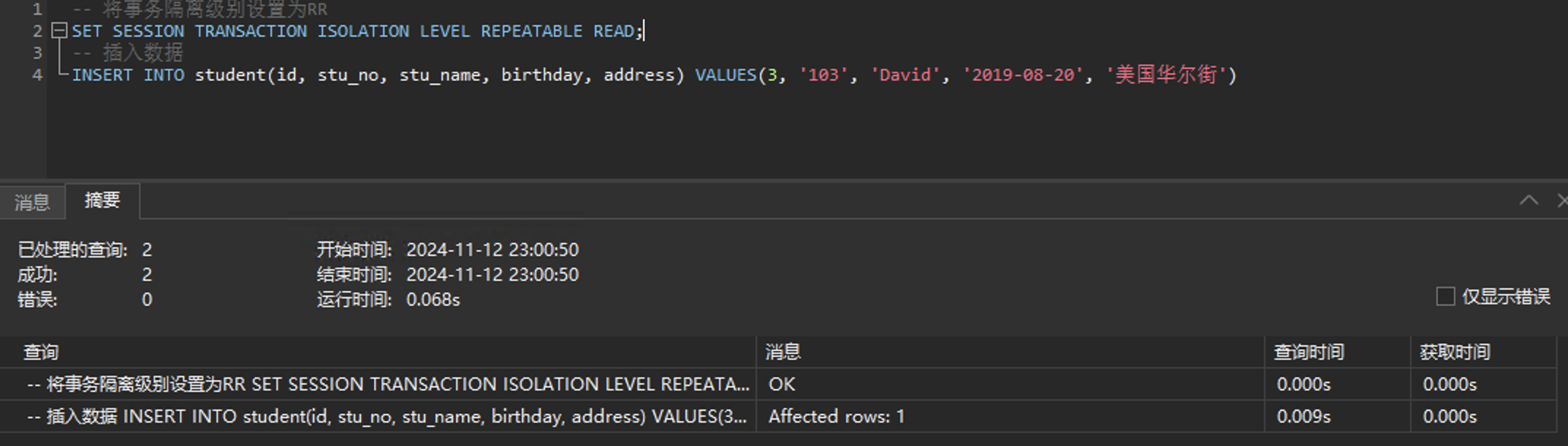
插入成功
接下来回到会话一,再次查询:
可以看到还是只有一条
但是如果开启一个新的事务却可以看到两条。所以在RR隔离级别下,确实解决了脏读、不可重复读和幻读问题
- 串行化(Serializable)
串行化是所有的事务都串行执行,当时所有问题都能够解决,这里不去验证了。
但是随着隔级别从上到下解决的问题越多,随之而来的自然是性能的牺牲。就像我们在架构设计的时候经常考虑的CAP理论一样,性能和成本只能尽量去平衡,鱼和熊掌不可兼得。好在对于数据一致性的这四个问题,除了脏读问题不能接受之外,其它几个问题在特定的业务场景下并不是完全不可接受,总的来说还是要结合自己的业务场景去选择。
对于InnoDB来说,默认的RR隔离级别基本上能满足我们绝大部分场景
